Nagios/OMD-Cluster mit Pacemaker/DRBD Teil 3
Bau eines hochverfügbaren Monitoring-SystemsTeil 3 – Einrichtung der Ressourcen
Nachdem wir in Teil 2 die Grundlagen für den Cluster (Netzwerkkonfiguration, Corosync-Ring) geschaffen haben, können wir uns nun den einzelnen Ressourcen im Cluster zuwenden.
Was sind Ressourcen?
Ressourcen sind im Cluster-Jargon die Teile eines geclusterten Dienstes,
welche auf einem oder mehreren Nodes zu laufen haben. Dahinter verbirgt
sich mehr als nur der Aufruf von omd start/stop – der Cluster hat z.B.
dafür zu sorgen, dass die virtuelle IP-Adresse, unter der der Server
immer ansprechbar sein soll, immer nur auf einem Node aktiv ist. Das
Filesystem, in welche OMD die Laufzeitdaten schreibt, darf bzw. kann nur
auf dem Node gemountet werden, auf dem auch der DRBD zum Master promoted
ist – und wenn, dann nur nach dem Promoten. Einen solch “atomaren”
Bestandteil wie z.b. den Mountvorgang des DRBD-Devices nennt man
Ressource. Wie in unserem OMD-Cluster die Ressourcen konstruiert und
in Abhängigkeit zueinander gebracht werden müssen, lesen Sie im
folgenden Absatz.
Definition von Ressourcen
Pacemaker bietet zur Definition von Ressourcen die komfortable crm-Shell (CRM= Cluster Resource Manager), die sogar die Vervollständigung von Schlüsselwörtern per Tabulator-Taste versteht. Kommandos in der crm-Shell sind immer nur auf einem Node abzusetzen, da die dadurch konfigurierte CIB (Cluster Information Base, eine XML-Datei, die Sie besser gar nicht erst suchen, geschweige denn von Hand editieren) automatisch auf alle Clusternodes repliziert. Starten Sie die crm-Shell:
root@nagios1:~# crm
crm(live)#Durch Eingabe von configure gelangen Sie eine Ebene tiefer, um die
live-CIB zu konfigurieren, help liefert allerlei nützliche Infos, up
befördert Sie wieder eine Ebene höher, während quit die Shell
verlässt.
Globale Parameter
Zunächst definieren wir im configure-Modus die Parameter, welche für
den ganzen Cluster gelten sollen.
crm(live)# property stonith-enabled="false" [enter]
property no-quorum-policy="ignore" [enter]
rsc_defaults resource-stickiness="1" [enter]Die crm-Shell schluckt so lange alle Kommandos, bis Sie diese committen.
Das Schlüsselwort show zeigt Ihnen die nun aktuelle Konfiguration:
crm(live)configure# commit [enter]
crm(live)configure# show [enter]
node nagios1
node nagios2
property $id="cib-bootstrap-options"
dc-version="1.0.8-042548a451fce8400660f6031f4da6f0223dd5dd"
cluster-infrastructure="openais"
expected-quorum-votes="2"
stonith-enabled="false"
no-quorum-policy="ignore"
rsc_defaults $id="rsc-options"
resource-stickiness="1"ping – die erste Cluster-Ressource
Mit “ping” steht dem Cluster eine einfache aber wirksame Methode zur Verfügung, seine, nennen wir es “Netzwerkgesundheit” festzustellen: vereinfacht gesagt lassen wir jeden Node eine Reihe Hosts im LAN im 10s-Intervall pingen (pro Ping default 5 Versuche). Damit ein kleiner Netzwerk-Schluckauf nicht gleich für einen Cluster-Schwenk sorgt, definieren wir mit “dampen” ein Delay von 20 Sekunden. Erst nach Ablauf dieser Gnadenfrist gilt ein negatives Ergebnis.
(Gehen Sie bei der Wahl der Ping-Hosts mit Bedacht vor und wählen Sie nur IP-Adressen, die in unmittelbarer Nähe zum Cluster und entsprechend erreichbar sind – schließlich soll das Verhalten der Clusters ja nicht schon dadurch beeinflusst werden, dass Ihr Kollege einen kleinen Windows-Server herunterfährt…)
Der Node mit dem besseren End-Resultat gewinnt. Würden wir diesen Ping nur als “primitive” definieren, liefe er jeweils nur auf einem Node – deshalb wird der Cluster mit der Direktive “clone” angewiesen, diese Ressource auf allen Nodes laufen zu lassen:
crm(live)configure# primitive pri_ping ocf:pacemaker:ping
> params dampen="20s" multiplier="1000"
> host_list="192.168.1.240 192.168.1.23 192.168.1.2"
> op monitor interval="5s"
crm(live)configure# clone clone_ping pri_ping
crm(live)configure# commit“Multiplier” gehört hier das Augenmerk: mit diesem Wert wird die Anzahl der erfolgreich gepingten Hosts multipliziert. Der hieraus errechnete Score sollte bei jedem Host 3000 betragen (3×1000):
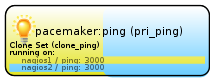
Weil wir uns nicht mit der GUI zufrieden geben, sondern auch auf der
Konsole prüfen wollen, wie es dem Cluster geht, rufen wir auf einem der
beiden Nodes das Kommando crm_mon auf – achten Sie auf die Scores,
die sollten beiden 3000 betragen (bzw. entsprechend der Anzahl der
Hosts, die Sie ihren Cluster pingen lassen). watch -n 1 ruft für uns
im 1-Sekunden-Interval crm_mon -1 -f auf, sodass wir den Status des
Cluster sekundengenau mitverfolgen können:
watch -n 1 'crm_mon -1 -f' [enter]
============
Last updated: Thu May 12 23:46:56 2011
Stack: openais
Current DC: nagios1 - partition with quorum
Version: 1.0.8-042548a451fce8400660f6031f4da6f0223dd5dd
2 Nodes configured, 2 expected votes
1 Resources configured.
============
Online: [ nagios1 nagios2 ]
Clone Set: clone_ping
Started: [ nagios1 nagios2 ]
Migration summary:
* Node nagios2: pingd=3000
* Node nagios1: pingd=3000Mit diesem Score werden nun Regeln verknüpft. Wir möchten, dass der Node, der den „besseren“ Ping-Score hat, gewinnt: alle Ressourcen sollen zu ihm umgezogen werden.
DRBD-Synchronisation
Zunächst werden wir das logical Volume “lvomd” zum Blockdevice des DRBDs ernennen, sowie ein Filesystem darauf einrichten. Diese Aufgabe nimmt einem die DRBD-MC in so kompakter Weise ab, dass wir diesmal – ausnahmsweise – die Shell meiden.
Im Abschnitt „Storage (DRBD)“ sehen Sie alle Blockdevices der beiden Nodes untereinander. Klicken Sie mit der rechten Maustaste auf das logical volume “lvomd” von nagios1 und wählen Sie

Im folgenden Assistenten definieren wir die DRBD-Ressource “romd” (‘r’ wie ‘resource’, ich bin ein Freund von Prefixen):
- Name: romd
- Device: /dev/drbd0
- Protocol: C/Synchronous
- On io error: detach
Im nächsten Dialog möchte der Assistent wissen, über welche Interfaces Sie das Device synchronisieren möchten. Für Nagios 1 und 2 ist jeweils anzugeben
- Interface: eth1 (10.1.1.10) bzw. (10.1.1.20)
- DRBD Meta disk: internal
- Port: 7788
Im darauffolgenden Fenster wählen wir “Create new meta-data & destroy data” und klicken auf “Create Meta-Data”. Nach einem klick auf “Next” können Sie in der im unteren Bildschirmrand eingeblendeten Kommandozeilen-Leiste sehen, dass DRBD-MC die Ressource bereits mittels “drbdadm up romd” hochgefahren hat.
Klicken wir auf “Next”, und lassen auf der DRBD-Ressource gleich ein ext4-Filesystem erzeugen:

Nach einer Weile ist das Filesystem auf dem Blockdevice erzeugt – und nach einem Click auf „Finish“ sollte das Endresultat sollte in etwa so aussehen:
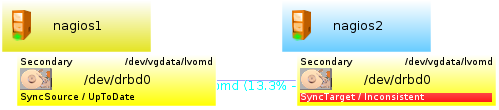
Wie Sie an der Prozentangabe unter der Verbindungslinie erkennen können, ist
die Synchronisation der beiden Devices bereits in vollem Gange. Auf der
Shell lässt sich dies überprüfen, in dem Sie /proc/drbd per cat
auslesen:
root@nagios2:~# watch -n 1 cat /proc/drbd
version: 8.3.10 (api:88/proto:86-96)
GIT-hash: 680ee9418871ccf23f46069b14fd5bef4e7c1e34 build by root@nagios2, 2011-05-12 17:28:45
0: cs:SyncTarget ro:Secondary/Secondary ds:Inconsistent/UpToDate C r-----
ns:0 nr:190540 dw:190540 dr:0 al:0 bm:11 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:212200
[========>...........] synced: 48.0% (212200/401356)K
finish: 0:02:41 speed: 1,308 (1,388) want: 250 K/secWie Sie vielleicht erkennen können, ist die “Syncer rate” nicht gerade schnell. Der Artikel “Configuring the rate of synchronisation” auf der DRBD-Seite erläutert detailliert, wie man die für sein System passende Syncer rate errechnet. Sie können diesen Wert nun entweder auf beiden Nodes in die Datei “/etc/drbd.d/romd.res” eintragen, oder hierzu einmal die GUI verwenden (=> Optionsleiste auf der rechten Seite), die dies gleich auf beiden Nodes für Sie erledigt:

Derzeit sind beide DRBD-Volumes im Status “secondary”:
root@nagios2:~# drbd-overview
0:romd Connected Secondary/Secondary UpToDate/UpToDate C r-----Lassen Sie uns nun eine Cluster-Ressource einrichten, die das Volume auf einem Node zum “primary” promoted. Wechseln Sie in die crm-shell und definieren Sie:
crm(live)configure# primitive pri_drbd_omd ocf:linbit:drbd [enter]
params drbd_resource="romd" [enter]
op monitor interval="5" [enter]
ms ms_drbd_omd pri_drbd_omd [enter]
meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true" [enter]
crm(live)# commit [enter]Die “primitive”-Deklaration definiert zunächst einmal die Cluster-Ressource vom Typ ocf:linbit:drbd und weist sie an, die DRBD-Ressource “romd” zu verwenden. Alle 5 Sekunden soll der Status überprüft werden. Die “ms”-Deklaration weist pri_drbd_omd als MultiState-Ressource aus, soll heißen: starte die Ressource zwar auf mehreren Nodes, wobei
- im ganzen Cluster nur 1 Master existieren darf (
master-max) - im ganzen Cluster genau zwei Instanzen dieses primitives laufen
dürfen (
clone-max) - pro Node nur eine Instanz dieses primitives laufen darf
(
clone-node-max) - pro Node nur 1 Master existieren darf (
master-node-max)
In der DRBD-MC werden Sie nach dem commit nun unter “Cluster Manager”-”Services” eine neue Ressource entdecken:
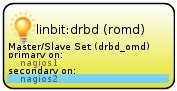
Dort, wo DRBD im Status Primary (bzw. die Multistate-Ressource im Status “Master”) läuft, wollen wir außerdem, dass das DRBD-Device gemountet wird. Legen Sie auf beiden Nodes einen Mountpunkt an:
mkdir /mnt/omddataDer Mount-Vorgang ist eine eigene Cluster-Ressource, die Sie in der crm-Shell anlegen:
crm(live)configure# primitive pri_fs_omd ocf:heartbeat:Filesystem [enter]
params device="/dev/drbd0" fstype="ext4" directory="/mnt/omddata/" [enter]
meta target-role="Started" [enter]
crm(live)# commit [enter]Und schon zeigt die GUI eine weitere Ressource an:
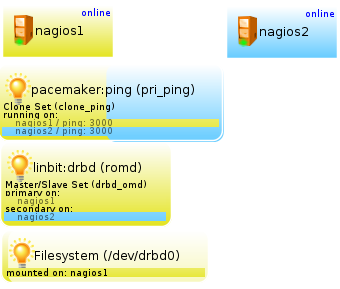
Falls “crm_mon” meldet, dass die Filesystem-Ressource auf keinem Node gestartet werden konnte…
Failed actions:
pri_fs_omd_start_0 (node=nagios1, call=10, rc=5, status=complete):
not installed
pri_fs_omd_start_0 (node=nagios2, call=13, rc=5, status=complete):
not installed…sollten Sie prüfen, ob die fuse-utils tatsächlich installiert sind. Es kann durchaus sein, dass sich die Filesystem-Ressource rot färbt, wenn pacemaker versucht hat, sie vor DRBD zu starten. Das sollte auch nicht verwundern – schließlich liegt das zu mountende Filesystem ja im DRBD. Setzen Sie in diesem Fall den Fehlerzähler der Filesystem-Ressource zurück:
crm resource cleanup pri_fs_romdbzw. per Rechtsklick in der GUI > „Reset Fail-Count“. Damit startet Pacemaker einen neuen Versuch, die Ressource – diesmal natürlich erfolgreich mit darunterliegendem DRBD – noch einmal zu starten.
Der aktuelle Zustand ist, das sollte nicht vergessen werden, momentan noch ein „Zufallsprodukt“. Pacemaker muss noch lernen, in welchen Abhängigkeiten die Ressourcen zueinander stehen.
Während meiner Tests fiel mir auf, dass der Cluster urplötzlich auf keinem der beiden Nodes mehr /dev/drbd0 mounten wollte, obwohl Mounten von Hand weiterhin funktionierte. Dem Logfile konnte ich nur noch entnehmen:
May 3 14:30:21 nagios1 Filesystem[4645]: ERROR: Couldn't sucessfully fsck filesystem for /dev/drbd0
May 3 14:34:50 nagios2 Filesystem[21338]: ERROR: Couldn't sucessfully fsck filesystem for /dev/drbd0
...Irgendwann entdeckte ich, dass der Ressource-Agent “Filesystem” noch kein ext4-Filesystem zu berücksichtigen scheint. Öffnen Sie auf beiden Nodes das Agent-Script:
vim /usr/lib/ocf/resource.d/heartbeat/Filesystem
...
case $FSTYPE in
ext3|reiserfs|reiser4| bla...bla|gfs2|none|lustre)
false;;
*)
true;;
esac
then
ocf_log info "Starting filesystem check on $DEVICE"
...Wenn das zu mountende Filesystem also nicht unter den genannten ist, möchte der Cluster zunächst eine Überprüfung durchführen. Sie können sich vorstellen, wie erwünscht dieser Effekt in dem Moment ist, in dem Node 1 ausgefallen ist und Node 2 nun möglichst schnell einspringen soll. Schreiben Sie also direkt hinter “ext3|” noch “ext4|”, sodass fsck fortan auch für ext4-Filesysteme überprungen wird. (Siehe auch Dokumentation des Bugs auf launchpad.net).
Service-IP
Natürlich wollen wir unseren Cluster nicht je nach aktivem Node mit unterschiedlicher IP-Adresse ansprechen müssen, und spendieren ihm deshalb eine Service-IP, die immer auf dem aktiven Node aktiviert werden soll. Dies bewerkstelligt die Ressource IPaddr2, welche auch gleich noch per ARP-Broadcast veranlasst, dass alle Clients ihren ARP-Cache mit der neuen MAC-Adresse aktualisieren. Die Parameter sollten weitgehend selbsterklärend sein:
crm(live)configure# primitive pri_nagiosIP ocf:heartbeat:IPaddr2 [enter]
op monitor interval="5s" timeout="20s" [enter]
params ip="192.168.55.30" cidr_netmask="24" iflabel="NagiosIP" [enter]
crm(live)# commit [enter]Apache2
Der eingangs installierte Apache ist ebenfalls eine Cluster-Ressource, denn er nimmt als Proxy alle Anfragen an und weiß, an welchen der pro Site gestarteten Schwesterprozesse er den Request weiterleiten muss. Stoppen Sie ihn und unterbinden Sie ebenfalls seinen Start wenn das System bootet:
invoke-rc.d apache2 stop [enter]
update-rc.d -f apache2 remove [enter]Nun legen wir ihn als Cluster-Ressource an:
crm(live)configure# primitive pri_apache ocf:heartbeat:apache [enter]
op monitor interval="5" timeout="20" [enter]
op start interval="0" timeout="60" [enter]
op stop interval="0" timeout="60" [enter]
params configfile="/etc/apache2/apache2.conf" testregex="body" [enter]
statusurl="http://localhost/server-status" [enter]
crm(live)# commit [enter]Pacemaker überwacht Apache, indem er seine status-Page aufruft. Per regex “body” prüft er, ob eine gültige HTML-Seite zurückgeliefert wird (natürlich können Sie den regex verfeinern). Wieder ein Blick in die DRBD-MC – Ihr Cluster sollte mittlerweile so aussehen:
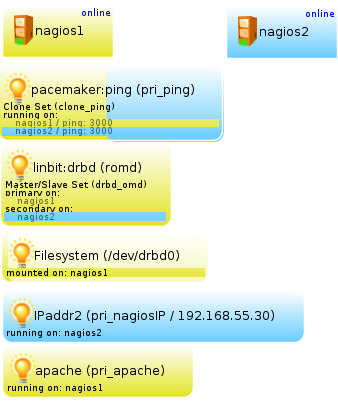
Wie Sie sehen, hat Pacemaker die Service-IP auf nagios2 gestartet. Im übernächsten Kapitel werden wir diesem Zustand mit constraints zuleibe rücken und die Ressourcen in ihrer Zusammengehörigkeit und Startreihenfolge so verzurren, dass sie in einem für uns konsistenten Zusammenhang laufen. Zunächst aber wenden wir uns OMD zu, welches wir fürs Clustering vorbereiten müssen.
Nagios/OMD-Cluster mit Pacemaker/DRBD – Teil 1 (Installation der Nodes)
Nagios/OMD-Cluster mit Pacemaker/DRBD – Teil 2 (Konfiguration der Pakete)
Nagios/OMD-Cluster mit Pacemaker/DRBD – Teil 3 (Einrichtung der Clusterressourcen)
Nagios/OMD-Cluster mit Pacemaker/DRBD – Teil 4 (OMD-Sites als Clusterressource)
Nagios/OMD-Cluster mit Pacemaker/DRBD – Teil 5 (Constraints)
Nagios/OMD-Cluster mit Pacemaker/DRBD – Teil 6 (Besonderheiten)